How to write a tree-sitter grammar in an afternoon
This article was discussed on Hacker News.
Every passing decade, it seems as if the task of implementing a new programming language becomes easier. Parser generators take the pain out of parsing, and can give us informative error messages. Expressive type systems in the host language let us pattern-match over a recursive syntax tree with ease, letting us know if we’ve forgotten a case. Property-based testing and fuzzers let us test edge cases faster and more completely than ever. Compiling to intermediate languages such as LLVM give us reasonable performance to even the simplest languages.
Say you have just created a new language leveraging the latest and greatest technologies in programming language land, what should you turn your sights to next, if you want people to actually adopt and use it? I’d argue that it should be writing a tree-sitter grammar. Before I elaborate what tree-sitter is, here’s what you’ll be able to achieve much more easily:
- syntax highlighting
- pretty-printing
- linting
- IDE-like features in your editor (autocomplete, structure navigation, jump to definition)
And the best part is that you can do it in an afternoon! In this post we’ll write a grammar for Imp, a simple imperative language, and you can get the source code here.
This post was inspired by my research in improving the developer experience for FORMULA and Spin.
Why tree-sitter?
Tree-sitter is a parser generator tool. Unlike other parser generators, it especially excels at incremental parsing, creating useful parse trees even when the input has syntax errors. And best of all, it’s extremely fast and dependency-free, letting you parse the entirety of the file on every keystroke in milliseconds. The generated parser is written in C, and there are many bindings to other programming languages, so you can programmatically walk the tree as well.
A tree-sitter grammar for Imp
Imp is a simple imperative language often used as an illustrative example in programming language theory. It has arithmetic expressions, boolean expressions and different kinds of statements including sequencing, conditionals and while loops.
Here’s an Imp program that computes the factorial of x and places the
result in y.
// Compute factorial
z := x;
y := 1;
while ~(z = 0) do
y := y * z;
z := z - 1;
end
Setting up the project
Check out the official tree-sitter development guide.
If you’re using Nix, run nix shell nixpkgs#tree-sitter
nixpkgs#nodejs-16-x to enter a shell with the necessary dependencies.
Note that you don’t need to have it set up to continue reading this post, since I’ll provide the terminal output at appropriate points.
Writing the grammar
Expressions
First we follow the grammar for expressions given in the chapter. Here it is for reference.
a := nat
| id
| a + a
| a - a
| a * a
| (a)
b := true
| false
| a = a
| a <= a
| ~b
| b && b
a corresponds to arithmetic expressions and b corresponds to
boolean expressions.
The easiest things to handle are numbers and variables. We can add the following rules:
id: $ => /[a-z]+/,
nat: $ => /[0-9]+/,
The grammar for arithmetic expressions can easily be translated:
program: $ => $.aexp,
aexp: $ => choice(
/[0-9]+/,
/[a-z]+/,
seq($.aexp,'+',$.aexp),
seq($.aexp,'-',$.aexp),
seq($.aexp,'*',$.aexp),
seq('(',$.aexp,')'),
),
Defining precedence and associativity
Let’s try to compile it! Here’s what tree-sitter outputs:
Unresolved conflict for symbol sequence:
aexp '+' aexp • '+' …
Possible interpretations:
1: (aexp aexp '+' aexp) • '+' …
2: aexp '+' (aexp aexp • '+' aexp)
Possible resolutions:
1: Specify a left or right associativity in `aexp`
2: Add a conflict for these rules: `aexp`
Tree-sitter immediately tells that our rules are ambiguous, that is, the same sequence of tokens can have different parse trees. We don’t want to be ambiguous when writing code! Let’s make everything left-associative:
program: $ => $.aexp,
aexp: $ => choice(
/[0-9]+/,
/[a-z]+/,
prec.left(1,seq($.aexp,'+',$.aexp)),
prec.left(1,seq($.aexp,'-',$.aexp)),
prec.left(1,seq($.aexp,'*',$.aexp)),
seq('(',$.aexp,')'),
),
However, something’s not quite right when we parse 1*2-3*4:

It’s being parsed as ((1*2)-3)*4, which is clearly a different
interpretation! We can fix this by specfiying prec.left(2,...) for
*. The resulting parse tree we get is what we want.

Note that in many real language specs, the precedence of binary operators is given, so it becomes pretty routine to figure out the associativity and precedence to specify.
Boolean expressions and statements
The grammars for boolean expressions and statements are similar, and can be found in the accompanying repository.
Testing the grammar
Phew, so now we have a grammar that tree-sitter compiles. How do we
actually run it? The tree-sitter CLI has two subcommands to help out
with this, tree-sitter parse and tree-sitter test. The parse
subcommand takes a path to a file and parses it with the current
grammar, printing the parse tree to stdout. The test subcommand
runs a suite of tests defined in a very simple syntax:
===
skip statement
===
skip
---
(program
(stmt
(skip)))
The rows of equal signs denote the name of the test, followed by the program to parse, then a line of dashes followed by the expected parse tree.
When we run tree-sitter test, we get a check if a test passed and a
cross if it failed, complete with a diff showing the expected
vs. actual parse tree (to illustrate the error I replaced the example
code with skip; skip instead):
tests:
✗ skip
✓ assignment
✓ prec
✓ prog
1 failure:
expected / actual
1. skip:
(program
(stmt
(seq
(stmt
(skip))
(stmt
(skip)))))
(skip)))
Syntax highlighting!
Believe it or not, that was pretty much all there is to writing a tree-sitter grammar! We can immediately put it to use by using it to perform syntax highlighting. Traditional syntax highlighting methods used in editors rely on regex and ad-hoc heuristics to colorize tokens, whereas since tree-sitter has access to the entire parse tree it can not only color identifiers, numbers and keywords, but also can do so in a context-aware fashion—for instance, highlighting local variables and user-defined types consistently.
The tree-sitter highlight command lets you generate syntax
highlighting
of your source code and render it in your terminal or output to HTML.
Tree-sitter’s syntax
highlighting
is based on queries. Importantly, we need to assign highlight names
to different nodes in the tree. We only need the following 5 lines
for this simple language. The square brackets indicate alternations,
that is, if any of the nodes in the tree match an item in the list,
then assign the given capture name (prefixed with @) to it.
[ "while" "end" "if" "then" "else" "do" ] @keyword
[ "*" "+" "-" "=" ":=" "~" ] @operator
(comment) @comment
(num) @number
(id) @variable.builtin
And here is what tree-sitter highlight --html on the factorial
program gives
// Compute factorial
z := x;
y := 1;
while ~(z = 0) do
y := y * z;
z := z - 1;
endNot bad! Operators, keywords, numbers and identifiers are clearly highlighted, and the comment being grayed out and italicized makes the code more readable.
Where to go from here?
Creating a tree-sitter grammar is only the beginning. Now that you have a fast, reliable way to generate syntax trees even in the presence of syntax errors, you can use this as a base to build other tools on. I’ll briefly describe some of the topics below but they really deserve their own blog post at a later date.
More highlighting
Syntax highlighting can become more informative semantically with tree-sitter. That is, we can have the syntax highlighter color local variable names one color, global variables another, distinguish between field access and method access, and more. Doing such nuanced highlighting using a regex-based highlighter is about as futile as trying to parse HTML with regex.
Editor integration
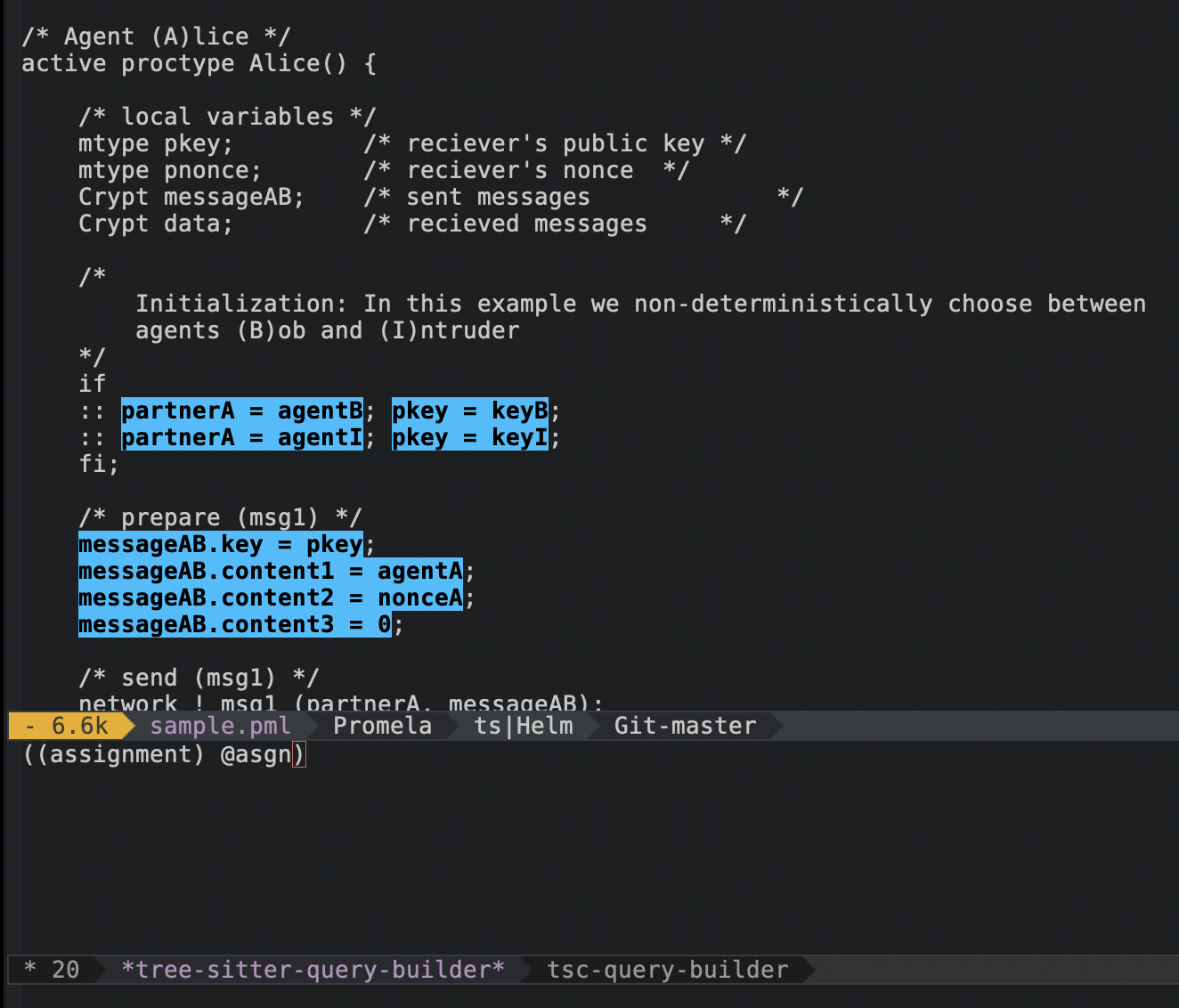
Tree-sitter grammars compile to a dynamic library which can be loaded into editors such as Emacs, Atom and VS Code on any platform (including WebAssembly). Using the extension mechanisms in each editor, you can build packages on top which can use the syntax tree for a variety of things, such as structural code navigation, querying the syntax tree for specific nodes (see screenshot), and of course syntax highlighting. Here’s an incomplete list of projects that use tree-sitter to enhance editing:
Linters
Tree-sitter has bindings in several languages. You can use this information and tree-sitter’s query language to traverse the syntax tree looking for specific patterns (or anti-patterns) in your programming language. To see this in action for Imp, see my minimal example of linting Imp with the JavaScript bindings. More details in a future post!
Final thoughts
Parsing technology has come a long way since the birth of computer science almost a century ago (see this excellent timeline of parsing). We’ve gone from being unable to handle recursive expressions and precedence to LALR parser generators and now GLR and fast incremental parsing with tree-sitter. It stands to reason that the tools millions of developers use every day to look at their code should take advantage of such developments. We can do better than line-oriented editing or hacky regexps to transform and highlight our code. The future is structural, and perhaps tree-sitter will play a big role in it!